PyTorch🔥
Torch是什么?一个火炬!其实跟
Tensorflow中Tensor是一个意思,当做是能在GPU中计算的矩阵就可以啦!
如果没玩过Tensorflow,Numpy总用过吧,也可以当做是
ndarray的GPU版!

PyTorch 的飞速发展
- 框架好不好用,咱们来看图说话!
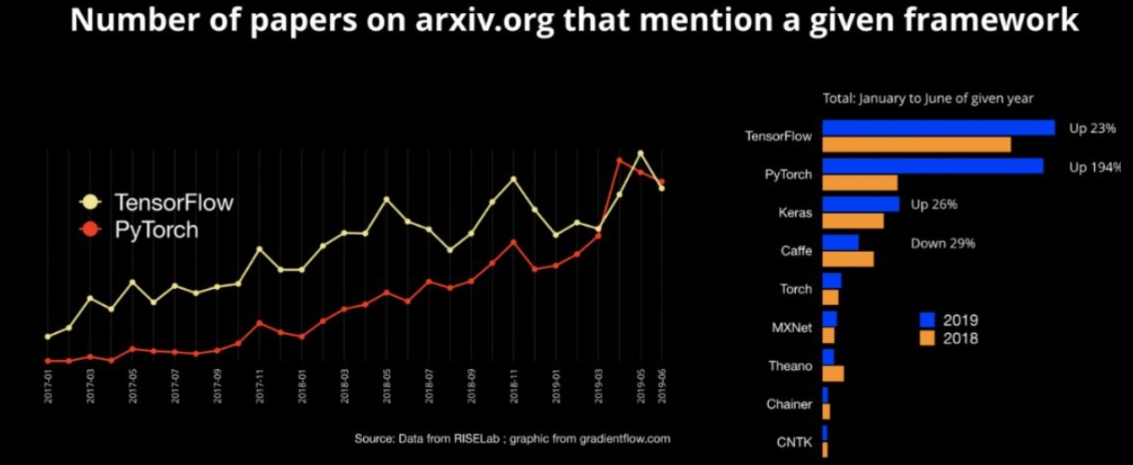
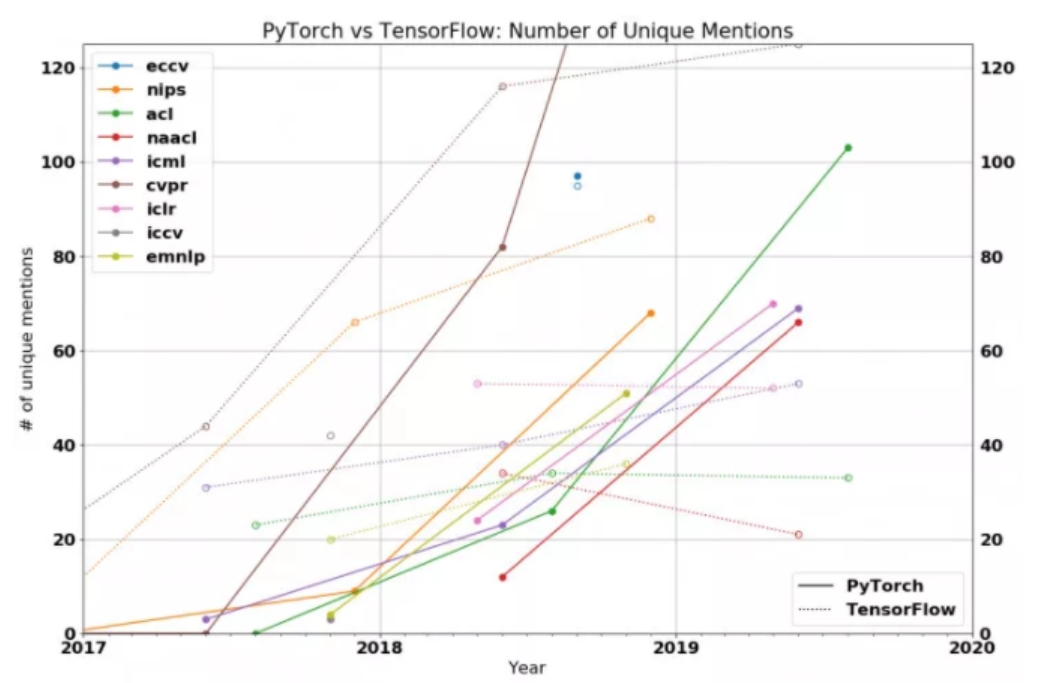
PyTorch可以说是现阶段主流的深度学习框架了,武林盟主之争大概是这个历史。。。
15年底之前
Caffe是老大哥,随着Tensorflow的诞生,霸占江湖数载,19年起无论从学术界还是工程界
PyTorch已经霸占了半壁江山!
安装Pytorch : 使用 pip 比较简单
可以自行官网下载:
下载 CUDA : https://developer.nvidia.cn/cuda-downloads
安装Pytorch : https://pytorch.org/
一、基本使用方法
创一个矩阵,有木有觉得很爽,如果用tensorflow的同学可能会这么觉得 ...
pythonx = torch.empty(5, 3) x """ tensor([[1.0469e-38, 9.3674e-39, 9.9184e-39], [8.7245e-39, 9.2755e-39, 8.9082e-39], [9.9184e-39, 8.4490e-39, 9.6429e-39], [1.0653e-38, 1.0469e-38, 4.2246e-39], [1.0378e-38, 9.6429e-39, 9.2755e-39]]) """
来个随机值
pythonx = torch.rand(5, 3) x """ tensor([[0.1452, 0.4816, 0.4507], [0.1991, 0.1799, 0.5055], [0.6840, 0.6698, 0.3320], [0.5095, 0.7218, 0.6996], [0.2091, 0.1717, 0.0504]]) """
初始化一个全零的矩阵
pythonx = torch.zeros(5, 3, dtype=torch.long) x """ tensor([[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]) """
直接传入数据
pythonx = torch.tensor([5.5, 3]) x tensor([5.5000, 3.0000])
感觉是不是跟Numpy差不多,其实这些框架的基本操作基本都是大同小异
x = torch.tensor([5.5, 3])
x = x.new_ones(5, 3, dtype=torch.double)
"""
这里的 new_ones 表示创建一个与原张量 x 具有
相同数据类型和存储设备(CPU或GPU)的新张量,并且这个新张量被初始化为全1。
"""
x = torch.randn_like(x, dtype=torch.float)
x
# ps : randn_like : rand (随机) n (normal distribution) like (像)
# torch.randn_like(x) 即 随机生成一个符合标准正态分布的数据, 其形状像x那样
"""
tensor([[ 0.5424, -1.1208, 2.2218],
[ 0.2297, -0.0828, 1.6972],
[-3.1776, -0.4144, 0.4833],
[ 1.2763, -0.7263, -0.9817],
[-0.6833, 0.1368, 0.4485]])
"""展示矩阵大小
pythonx.size() # torch.Size([5, 3])
基本计算方法
pythony = torch.rand(5, 3) x + y """ tensor([[ 0.6497, -0.5561, 2.2990], [ 0.5333, 0.4522, 2.1114], [-2.4560, 0.1690, 1.2198], [ 2.0695, -0.5944, -0.3466], [-0.2388, 0.5630, 0.8880]]) """pythontorch.add(x, y) #一样的也是加法 """ tensor([[ 0.6497, -0.5561, 2.2990], [ 0.5333, 0.4522, 2.1114], [-2.4560, 0.1690, 1.2198], [ 2.0695, -0.5944, -0.3466], [-0.2388, 0.5630, 0.8880]]) """
索引
pythonx[:, 1] # tensor([-1.1208, -0.0828, -0.4144, -0.7263, 0.1368])
view操作可以改变矩阵维度pythonx = torch.randn(4, 4) y = x.view(16) z = x.view(-1, 8) print(x.size(), y.size(), z.size()) # torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
与Numpy的协同操作
python# tensor --> array : a = torch.ones(5) b = a.numpy() b # array([1., 1., 1., 1., 1.], dtype=float32)python# array --> tensor import numpy as np a = np.ones(5) b = torch.from_numpy(a) b # tensor([1., 1., 1., 1., 1.], dtype=torch.float64)
二、Tensor の 常见形式
- 0 : scalar ( 标量 )
- 1 : vector ( 向量 )
- 2 : matrix ( 矩阵 )
- 3 : n-dimensional tensor ( n 维张量 )
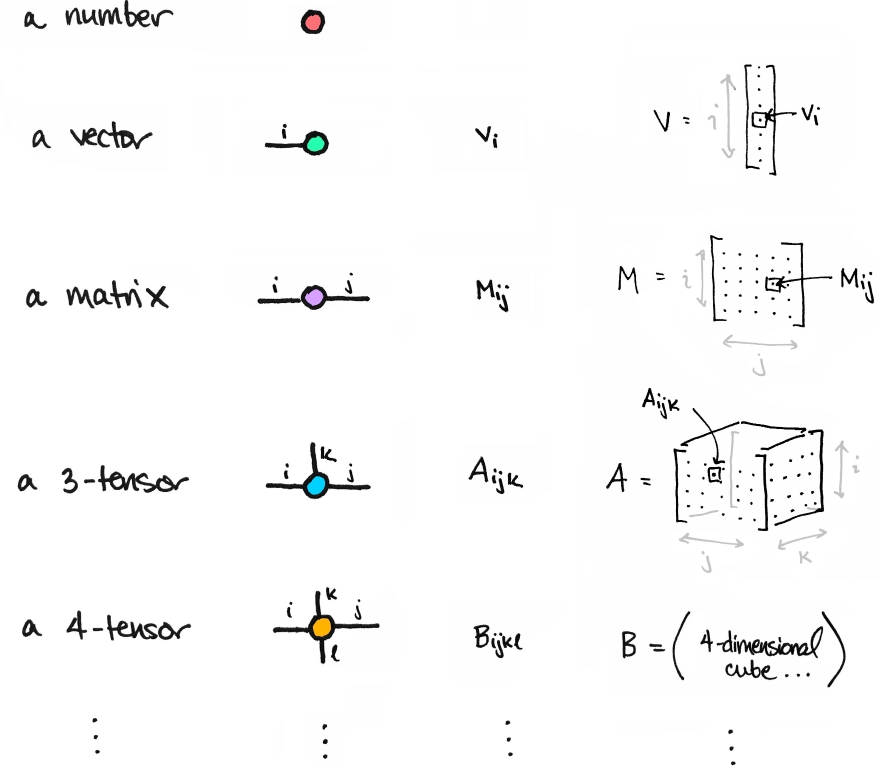
import torch
from torch import tensor- Scalar
通常就是一个数值
pythonx = tensor(42.) x # tensor(42.)python# Scalar 维度 x.dim() # 0python2 * x # tensor(84.)pythonx.item() # 42.0
- Vector
例如:
[-5., 2., 0.],在深度学习中通常指特征,例如词向量特征,某一维度特征等
v = tensor([1.5, -0.5, 3.0])
v
# tensor([ 1.5000, -0.5000, 3.0000])# Vector维度
v.dim()
# 1v.size()
# torch.Size([3])- Matrix
一般计算的都是矩阵,通常都是多维的
M = tensor([[1., 2.], [3., 4.]])
M
"""
tensor([[1., 2.],
[3., 4.]])
"""# 矩阵乘法使用 : matmul
# 对应英文 : matrix multiplication
M.matmul(M) # M 对自身进行矩阵乘法
"""
tensor([[ 1., 4.],
[ 9., 16.]])
"""tensor([1., 2.]).matmul(M)
# tensor([ 7., 10.])三、auto-grad 机制
框架干的最厉害的一件事就是帮我们把反向传播全部计算好了!!
需要求导的,可以手动定义:
python# 方法1 x = torch.randn(3,4,requires_grad=True) x """ tensor([[ 0.8552, 1.0131, -0.3288, 1.7462], [-1.0609, -0.0839, 1.6542, -1.1565], [ 1.6595, 3.0089, 0.2518, 0.6585]], requires_grad=True) """ # 可见,定义了求导会显示在打印格式里python#方法2 x = torch.randn(3,4) x.requires_grad=True x """ tensor([[ 0.8552, 1.0131, -0.3288, 1.7462], [-1.0609, -0.0839, 1.6542, -1.1565], [ 1.6595, 3.0089, 0.2518, 0.6585]], requires_grad=True) """
b = torch.randn(3,4,requires_grad=True)
b
"""
tensor([[ 1.3261, 1.7129, -0.8090, 1.9001],
[ 0.2046, 0.4733, 0.3893, -0.6391],
[ 0.5718, 0.8078, -0.3215, 0.0563]], requires_grad=True)
"""t = x + b
t
"""
tensor([[ 2.1813, 2.7260, -1.1378, 3.6464],
[-0.8563, 0.3894, 2.0435, -1.7956],
[ 2.2314, 3.8167, -0.0697, 0.7148]], grad_fn=<AddBackward0>)
"""y = t.sum()
y
# tensor(13.8900, grad_fn=<SumBackward0>)# 反向传播
y.backward()b.grad
"""
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
"""虽然没有指定
t的requires_grad但是需要用到它,也会默认的
x.requires_grad, b.requires_grad, t.requires_grad
# (True, True, True)
- 举个例子:
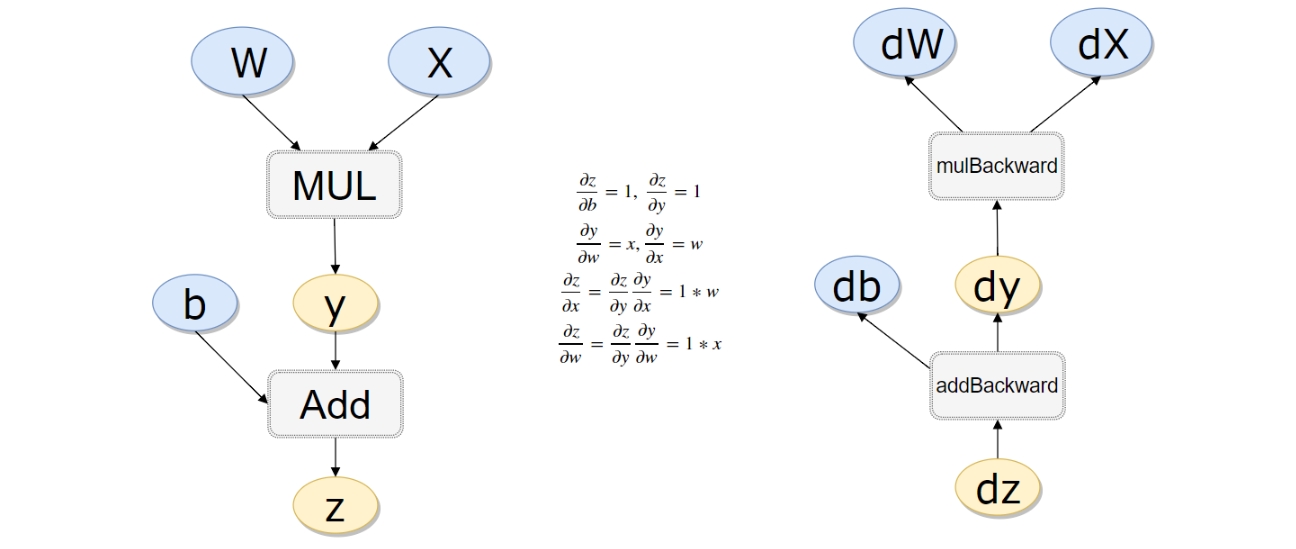
- 计算流程
python#计算流程 x = torch.rand(1) b = torch.rand(1, requires_grad = True) w = torch.rand(1, requires_grad = True) y = w * x z = y + bpythonx.requires_grad, b.requires_grad, w.requires_grad, y.requires_grad # 注意y也是需要的 # (False, True, True, True)python# 查看是否为叶子结点 x.is_leaf, w.is_leaf, b.is_leaf, y.is_leaf, z.is_leaf # (True, True, True, False, False)
- 反向传播计算
pythonz.backward(retain_graph=True) # 如果不清空会累加起来python# z 对 w 的偏导 w.grad # tensor([0.2051])python# z 对 b 的偏导 b.grad # tensor([1.])python# 因为前面图我们手算得 z 对 w 的偏导等于 x # 可以查看一下 x 的值验证一下 x # tensor([0.2051])
四、浅尝线性回归模型
先构造一组输入数据 X 及其对应的标签 y
pythonx_values = [i for i in range(11)] x_train = np.array(x_values, dtype=np.float32) x_train = x_train.reshape(-1, 1) x_train.shape # (11, 1)pythony_values = [2*i + 1 for i in x_values] y_train = np.array(y_values, dtype=np.float32) y_train = y_train.reshape(-1, 1) y_train.shape # (11, 1)
- 线性回归模型
其实线性回归就是一个不加激活函数的 全连接层 ( Linear )
# 这行代码定义了一个名为LinearRegressionModel的类,它继承自nn.Module
# nn.Module是PyTorch中所有神经网络模块的基类
# 这意味着 LinearRegressionModel 是一个神经网络模块
class LinearRegressionModel(nn.Module):
# 这是一个构造函数,用于初始化LinearRegressionModel类的实例
def __init__(self, input_dim, output_dim):
# input_dim代表输入特征的维度
# output_dim代表输出的维度 (在回归问题中通常是1)。
# 下面super()调用了父类nn.Module的构造函数
# 用于正确初始化父类。
super(LinearRegressionModel, self).__init__()
# 这行代码创建了一个线性层 (全连接层) , 并将其赋值给self.linear
self.linear = nn.Linear(input_dim, output_dim)
# 这是一个前向传播函数,定义了数据通过模型时的计算流程。
def forward(self, x):
# 这行代码将输入数据 x 传递给之前定义的线性层self.linear,进行线性变换。
out = self.linear(x)
# 返回经过线性变换后的结果out
return out# 输入维度 为 1
input_dim = 1
# 输出维度为 1
output_dim = 1
model = LinearRegressionModel(input_dim, output_dim)
model
"""
LinearRegressionModel(
(linear): Linear(in_features=1, out_features=1, bias=True)
)
"""指定好参数和损失函数
epochs = 1000 # 进行多少次训练(迭代)
learning_rate = 0.01 # 学习率
# 设置优化器为 SGD (随机梯度下降,Stochastic Gradient Descent)
# model.parameters() : 指定对我们定义的model的参数进行优化
# lr=learning_rate : 指定学习率
# ps: 优化器可以帮助我们 更新权重参数 即 y = kx + b 里面的 k 和 b 达到训练的效果
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 设置损失函数为 均方误差 (Mean Squared Error, MSE)
# 损失函数可以让我们知道预测值和真实值差多远,然后我们可以用优化器去调整
criterion = nn.MSELoss()训练模型:
for epoch in range(epochs):
# 因为range 从 0 开始的,我们每次都加一,就是从1开始算
# epoch 范围 1 - 1000
epoch += 1
# 注意转行成tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
# 梯度要清零每一次迭代
# 不清零的话,梯度会累加
optimizer.zero_grad()
# 前向传播
# 在PyTorch中,当你创建一个模型的实例并调用它时,例如model(inputs)
# PyTorch会自动调用这个模型实例的forward方法。
# 这是PyTorch的一个设计特点,使得模型的使用更加简洁和直观
# 也就是说下面这行代码等同于 outputs = model.forward(inputs)
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 更新权重参数
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
"""
epoch 50, loss 0.008274978958070278
epoch 100, loss 0.004719749093055725
epoch 150, loss 0.0026919401716440916
epoch 200, loss 0.0015353981871157885
epoch 250, loss 0.0008757374598644674
epoch 300, loss 0.0004994918708689511
epoch 350, loss 0.00028488683165051043
epoch 400, loss 0.00016248888277914375
epoch 450, loss 9.267879067920148e-05
epoch 500, loss 5.285888255457394e-05
epoch 550, loss 3.015184120158665e-05
epoch 600, loss 1.7196194676216692e-05
epoch 650, loss 9.807815331441816e-06
epoch 700, loss 5.593081368715502e-06
epoch 750, loss 3.1907097763905767e-06
epoch 800, loss 1.8201473039880511e-06
epoch 850, loss 1.0386996791567071e-06
epoch 900, loss 5.916471650380117e-07
epoch 950, loss 3.374661332600226e-07
epoch 1000, loss 1.925896526699944e-07
"""测试模型预测结果:
pythonpredicted = model(torch.from_numpy(x_train).requires_grad_()).data.numpy() predicted """ array([[ 0.99918383], [ 2.9993014 ], [ 4.9994187 ], [ 6.9995365 ], [ 8.999654 ], [10.999771 ], [12.999889 ], [15.000007 ], [17.000124 ], [19.000242 ], [21.000359 ]], dtype=float32) """ # ps : 创建的x是 0 - 10 # 表达式 : y = 2x + 1 # 对应的 y 则是 1 , 3 , 5 , 7 , 9 .... # 可见我们预测得十分准确了
模型的保存与读取
pythontorch.save(model.state_dict(), 'model.pkl')pythonmodel.load_state_dict(torch.load('model.pkl'))
- 使用GPU进行训练
其他步骤都一样,只是需要把数据和模型传入到
CUDA里面就可以了下面 绿色代码高亮 是需要补充的代码
import torch
import torch.nn as nn
import numpy as np
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
input_dim = 1
output_dim = 1
model = LinearRegressionModel(input_dim, output_dim)
# 设置训练设备 device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 模型放入到 device
model.to(device)
criterion = nn.MSELoss()
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 1000
for epoch in range(epochs):
epoch += 1
inputs = torch.from_numpy(x_train).to(device)
labels = torch.from_numpy(y_train).to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
"""
epoch 50, loss 0.17900052666664124
epoch 100, loss 0.10209517180919647
epoch 150, loss 0.05823122709989548
epoch 200, loss 0.03321290388703346
epoch 250, loss 0.01894339732825756
epoch 300, loss 0.010804574005305767
epoch 350, loss 0.0061625102534890175
epoch 400, loss 0.00351485563442111
epoch 450, loss 0.0020047335419803858
epoch 500, loss 0.0011434393236413598
epoch 550, loss 0.0006521626492030919
epoch 600, loss 0.00037196357152424753
epoch 650, loss 0.00021215935703366995
epoch 700, loss 0.00012100616004317999
epoch 750, loss 6.902093446115032e-05
epoch 800, loss 3.9368082070723176e-05
epoch 850, loss 2.245399446110241e-05
epoch 900, loss 1.2807114217139315e-05
epoch 950, loss 7.304930477403104e-06
epoch 1000, loss 4.166262442595325e-06
"""模型预测:
python# 把 x_train 转变成张量 tensor 然后设定requires_grad_() 再把这个 to CUDA # 因为一开始 model 在 CUDA 而数据在 CPU 必须两个都在同一个device才能计算 predicted = model(torch.from_numpy(x_train).requires_grad_().to(device)) predicted """ tensor([[ 0.9962], [ 2.9967], [ 4.9973], [ 6.9978], [ 8.9984], [10.9989], [12.9995], [15.0000], [17.0006], [19.0011], [21.0017]], device='cuda:0', grad_fn=<AddmmBackward0>) """
NumPy不支持直接与GPU上的数据交互
需要把数据转成 array 的话 需要拿回到 CPU
python# 首先将预测结果移动到CPU predicted_cpu = predicted.cpu() # 然后将结果转换为NumPy数组 predicted_numpy = predicted_cpu.data.numpy() predicted_numpy """ array([[ 0.9962031], [ 2.9967499], [ 4.9972963], [ 6.9978433], [ 8.99839 ], [10.998937 ], [12.999483 ], [15.00003 ], [17.000576 ], [19.001123 ], [21.00167 ]], dtype=float32) """
至此,我们写出了我们第一个神经网络模型!! 🎉